RTILA considers 2 types of datasets.
We go to focus on the LIST type. They appear as collections, like lists, tables, and grids that from time to time are paginated (numbered, load more, arrows, or similar methods).
If we consider an e-commerce, the LIST dataset would be the category.
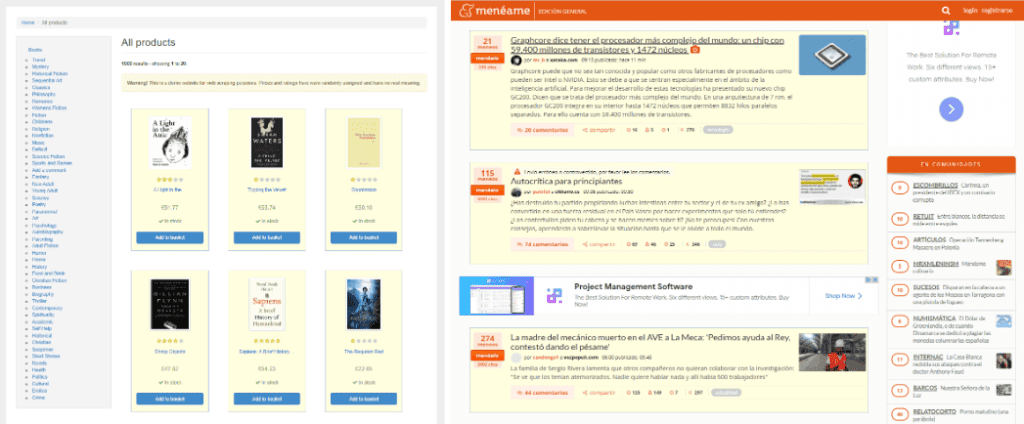
In the image, you can detect those repeating structures in yellow.
As you can imagine, a page could have many different kinds of collections.
For example, the menu, the products, the featured products, buy together products, the cart…
When we create our dataset, RTILA will guess where is located the repeating structure.
Sometimes the structure can be hard to guess, and on those special times we can manually enter the reference on the Custom collection field.
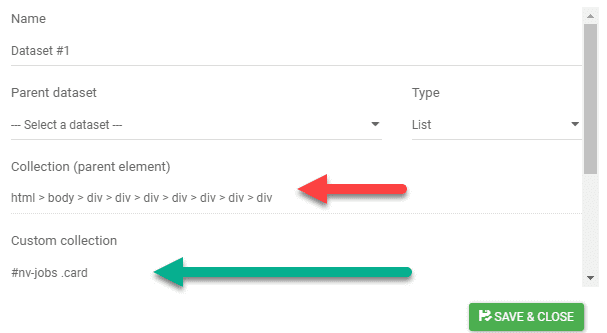
The number of selected elements in the collection needs to match the total number of rows, cards, or elements that we need to extract.
That will help RTILA to loop between all the elements.