Types of Crawlers & Use Cases #
RTILA Studio has 3 types of Crawler commands with slight differences but they overall work the same way. The differentiation is about the location of the links/pages that are to be crawled, whether they are “Internal”, “External” pages to the website we are on, or a mix of both.
The Crawler command is a powerful scrapping enabler that automatically recognizes and crawls web links of a given page, in a complete (all links) or selective manner (conditional logic).
In addition the Crawler is equipped with a Multi-threading capacity that allows you to crawl and open multiple tabs at the same time and significantly increase the speed of your automation. Assuming no firewall limits exist, the Crawler could crawl 10 pages per second or even more.
Crawler Configuration #
A great number of configurations are available for you to define and fine tune your crawler automation flow.
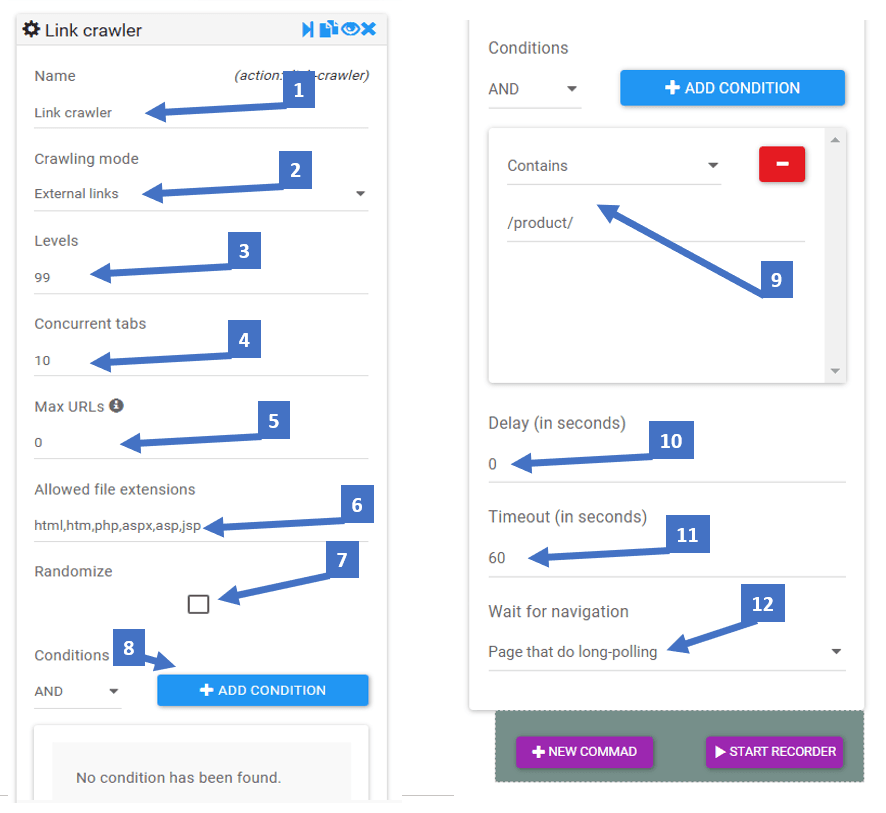
- To rename your crawler block
- Type of the crawler
- Depth of crawling. If 1 it will only crawl the links available on that page. If set to 2 it will crawl all the links of that page and also crawl the links inside the secondary pages.
- Number of tabs that are opened at the same time. Up to 10 if your internet connection and the website are fast. Otherwise a safer cruise speed is 3 to 5.
- If you want to limit the number of pages crawled, otherwise leave zero to crawl everything.
- Types of file extensions you want to include
- Check if you want to create a “human like” random crawling instead of sequential top to bottom order.
- You can add conditions for the Crawler to ignore or exclusively focus on URLs with specific keyword appearing (or not) in the URLs.
- Here it will only crawl links that contain “/product/”
- If you want to add a delay before each link opening
- Timeout for when one of the tabs/links is not loading properly
- Specify what you want to wait for in terms of page loading status.
Once you have setup your Crawler for mass data acquisition, you can just add an “Extract” command inside this block to ensure that the data properties you have set in the inspection panel are captured for each crawled page.
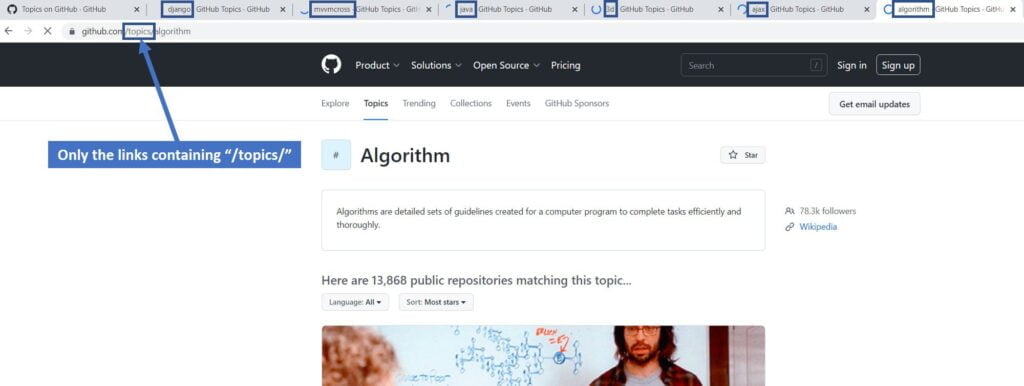
Crawler in action #
Below is a screenshot of our crawler going through the topics pages of GitHub to open all the links that contain “/topics/” in the URL. The multithreading is set to 7 tabs (includes the starting page) as this was the most reliable speed for our internet connection. The same can be achieved for any type of listing or directory website that contains structured internal or external links. Our crawler is able to crawl over 1 Million internal links of a specific directory, depending on the security threshold and load capacity of the target website and we advise to span the crawler over a longer period of time and a lower number of concurrent tab for better and more ethical results. RTILA is very stable so take it as a Marathon not a Sprint and pace your automation.